来源 | 微信公众号 大数据的朋友
数据湖是⼀个集中式存储库,以任意规模存储所有结构化和⾮结构化数据。可以按原样存储数据(⽆需先对数据进行结构化处理),并运⾏不同类型的分析 ‒ 从控制⾯板和可视化到⼤数据处理、 实时分析和机器学习等以指导做出更好的决策。
狭义的数据湖指的是数据湖存储,即可以存放海量数据(各种格式)的地⽅,包括Hadoop的⽂件系统HDFS或者云上的对象存储系统S3都属于这个范畴。⼴义的数据湖除了数据湖存储,还包括数据湖的管理和分析,即提供⼀整套⼯具,提供数据⽬录(Data Catalog)服务以及统⼀的数据访问。
1. 数据湖产生的背景
在互联早期,各个公司的数据量不大,而且较单一,因此整个数据架构比较简单,主要是基于关系型数据库搭建。关系型数据库提供了数据的收集、存储和分析,数据质量比较高,但是能够支撑的数据量有限。
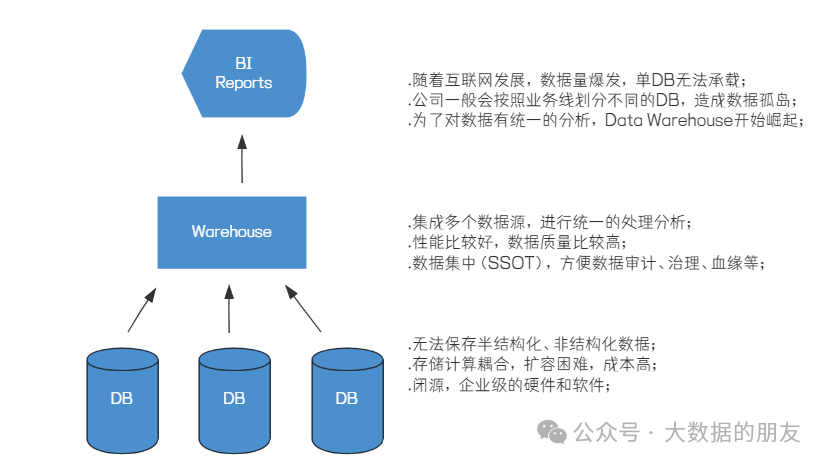
随着互联网的爆发,数据量爆发式增长,原有的数据架构开始暴露出问题:单个关系型数据库无法支撑庞大的数据量。于是公司会按照业务线等方式,把数据拆分,不同的数据库保存不同的数据,比如分别保存订单数据、用户数据等。虽然这种方式在一定程度上解决了问题,但它同时引入了另外一个问题:数据孤岛。如果业务想跨数据库进行分析,会非常困难,这严重影响了数据的可用价值。
在这个背景下,数据仓库(Data Warehouse)开始崛起。数据仓库可以集成多个数据库的数据,进行统一的处理分析,从而解决数据孤岛问题。
但同时数据仓库也存在各种各样的问题,其中很关键一点是成本相对较高,特别是保存数据量很大的话,会给公司带来比较大的成本压力。而且采用商业版数据仓库的话,由于技术闭源,且依赖特定的企业级服务器,会让公司和商业数仓背后的公司产生强绑定的风险,这些都是大公司所忌惮的。
2. Hadoop的出现
这一切问题在Hadoop问世后都发生了重大转变,Hadoop脱胎于Google的“三驾马车”,借助Google的先进理念,再通过开源的方式提供给广大用户,Hadoop成为了大数据分析的分水岭。企业从闭源昂贵的商业数仓转向开源免费的Hadoop,并且Hadoop可以保存多种多样的数据,包括文本、图片、音视频等。
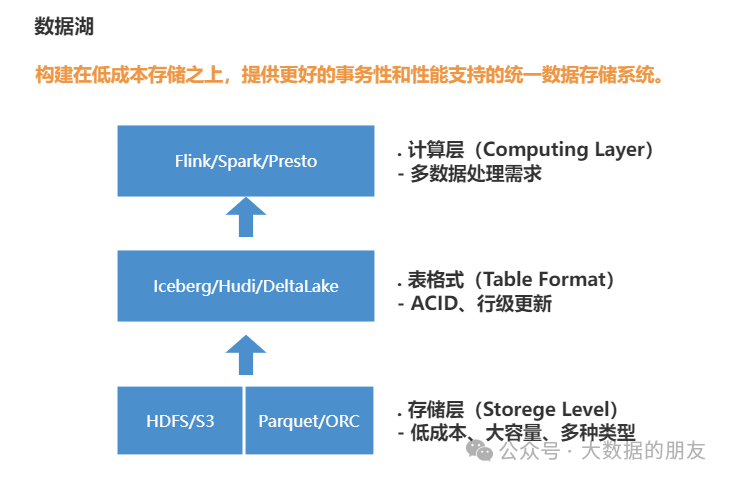
Hadoop的⼀⼤优势是低成本,且在低成本的优势之上,Hadoop提供了良好的容错性、扩展性,为不断涌现的数据提供了有力的存储和计算支撑。
Hadoop的⽕热也引来了不少⾮议,数据库领域的⼈指责Hadoop在“开历史的倒⻋”。以数据库领域的多年经验,有几条准则是很重要的:
- 数据⼀定要有Schema;但是Hadoop体系⼀开始是没有Schema概念的,⼀份数据的格式是什么,⼀般隐藏在代码中,或者写这份数据的⼈的脑⼦⾥,给其他⼈使⽤数据造成了很⼤的障碍。当然这个问题在Hive出现后已经很⼤地改观了。
- ⾼级别的访问语⾔(主要指SQL)很重要;在他们看来,写MapReduce代码太反⼈类了,跟写汇编似的,很多⼈搞不定。
除此之外,Hadoop还有⼀些数据库领域很关键的特性缺失了:
- 不⽀持事务,写⼊数据的作业如果挂了可能写⼊脏数据被下游读取到。
- 数据和Schema可能不匹配,如果写⼊了不符合Schema的数据,下游在处理的时就会有各种异常。
- 不⽀持索引、不⽀持更新等。
3. 基于Hive构建的传统数仓的局限性
- 数据运转效率低。数仓模型本⾝的研发与迭代成本⽐较⾼,⽣产速度赶不上需求速度,这就导致 我们的创新想法落地、业务策略迭代等都会被按下暂停键;
- 端到端的数据变更困难。业务的快速迭代导致了基础数据 schema 频繁变更,⽽每次数据 schema 变更都需要变更数据仓库中的存量数据并且更新升级全链路,⼤⼤拖慢了业务的迭代效 率
- 未提供较完善ACID语义⽀持。由于转储作业中断、INSERT OVERWRITE、Partition修改、 Schema修改等相关变动,很难隔离对下游任务的影响;
- 近实时分析CDC数据困难。基于Hive构建的数仓对Update和Delete操作⽀持并不友好,往往需要 额外的操作实现binlog数据的正确处理和分析;
- 机器学习流程更倾向于使⽤未加⼯的原始数据,通过特征提取和模型开发,⽤于模型在线推理;
- 难以提供近实时报表。业务要实现⼩时级或分钟级的近实时报表。
4. Hadoop + Data Warehouse
Hadoop虽然存在这样那样的缺点,但是事实证明,它依然⾮常受欢迎,因为它确实解决了其他技术⽆法解决的问题。
那么如何解决Hadoop本⾝的缺陷呢,很简单,用户选择把Hadoop和数据仓库结合起来使⽤:
Hadoop以其⼤容量低成本的特性,保存最原始的数据,这部分数据⽐较全⾯,但是质量可能不是⾮ 常⾼。对于关键的数据,通过ETL处理后,导⼊到数据仓库中,提供更好的查询性能,提供更好的数 据质量,⽀撑企业内部的BI和报表需求。
看起来很美好,但是可以看出⼜回到了早期存在的问题,数据孤岛问题。往往同⼀份数据在Hadoop 和数据仓库中都有⼀份,除了造成数据冗余、成本浪费,还造成了数据产出⼝径不⼀致问题,应该以 哪个系统的数据为准有时候说不清楚;另外,这种数据架构带来了运维上的困难,⽐如Schema的变 更很容易导致ETL链路的各种问题,这些都严重影响了从数据到价值的转换效率。
数据湖技术
用户需要有这样⼀种系统,它既具备Hadoop的低成本⼤容量的优势,⼜具备数据仓库的ACID事务等能⼒。如果有⼀套技术⽅案能够⽀撑如上需求的话,那么就可以很⼤程度上解决Hadoop+Data Warehouse搭配使⽤带来的各种问题。
数据湖是⼀种融合了Hadoop和数仓优势的技术。数据湖构建在低成本分布式存储之上,提供更好的事物和性能⽀持的统⼀数据存储系统。
那不是说就不需要数据仓库了,从短期来看是做不到的,对于性能要求⽐较⾼的查询等需求,依然需要数据仓库来解决。但按⼆⼋原则,如果80%的数据处理需求通过数据湖⼀套技术架构就能解决的话,就已经能够给业务带来很大价值了;无论在效率上还是成本上,都会带来很大的优势。业界有人偏向长期共存,有人偏向于数据湖架构逐步统⼀市场,目前暂⽆定论。
5. 数据湖与数据仓库对比
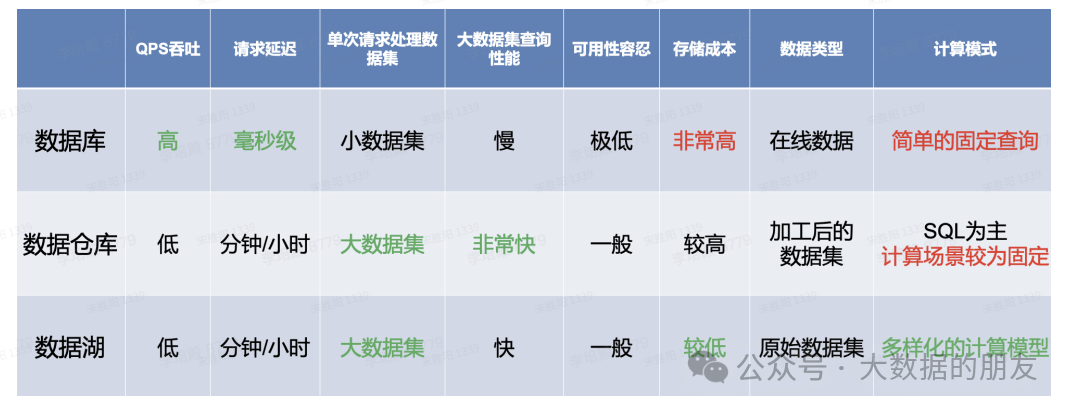
以下是数据湖技术和数据仓库的⼀个简单对比:
数据仓库是⼀个优化的数据库,⽤于分析来自事务系统和业务线应⽤程序的关系数据。事先定义数据结构和Schema以优化快速SQL查询,其中结果通常⽤于操作报告和分析。数据经过了清理、丰富和转换,因此可以充当用户可信任的“单⼀信息源”。
数据湖有所不同,因为它存储来自业务线应⽤程序的关系数据,以及来自移动应⽤程序、IoT设备和社交媒体的非关系数据。捕获数据时,未定义数据结构或Schema。这意味着可以存储所有数据,而不需要精心设计也无需知道将来可能需要哪些问题的答案。可以对数据使用不同类型的分析(如SQL查询、⼤数据分析、全⽂搜索、实时分析和机器学习)来获得结果。
| 特性 | 数据仓库 |
数据湖 |
| 数据 | 来自事务系统、运营数据库和业务线应用程序的关系数据 | 来自IOT设备、网站、移动应用程序的非关系和关系数据 |
| Schema | 设计在数据仓库实施之前(写入型Schema) | 写入在分析时(读取型Schema) |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果只需较低存储成本 |
| 数据质量 | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据 |
| 用户 | 业务分析师 | 数据科学家、数据开发和业务分析师 |
| 分析 | 批处理报告、BI和可视化 | 机器学习、预测分析、数据发现和分析 |

数据湖优先的设计拥有更⾼的灵活性。数据湖的数据存储形式和结构可以不预先定义,可以是结构化的,也可以是半结构化的。计算引擎可以根据不同的场景读写数据湖中存储的数据,这意味着在对数进行分析和处理时能获取到数据全部的初始信息,使⽤也更灵活,⾼效。
数据仓库优先的设计,能够做到更加规范化的数据管理。数据进入数据仓库前,通常预先定义schema,数据开发需要预先根据业务进⾏建模,构建数据模型,用户通过数据服务接⼝或者计算引擎访问数据模型来获取干净和规范的数据。
总结:本文介绍了数据仓库出现的背景,以及数据湖解决了数据仓库的哪些痛点,数据湖有哪些特性。下期我们将介绍数据湖有哪几种开源实现方式及其实现原理,如何构建流批一体的湖仓架构。
版权声明及安全提醒:本文转自网络平台,文章仅代表作者观点,不代表「金融文库」立场。相关版权归原作者所有,「金融文库」仅提供免费交流与学习,相关内容与材料请勿用于商业。我们感谢每一位原创作者的辛苦付出与创作,如本转载内容涉及版权及侵权问题,请及时联系我们客服处理(微信号:JRwenku8),谢谢!


