分享嘉宾|大鱼 腾讯 T11数据工程师
出品社区|DataFun
分为四个章节:
1. 数据治理的概况和解法
2. 腾讯 PCG 的元仓建设:专注特征挖掘、构建治理引擎基石
3. 资产分体系:开放、可持续迭代的资产分体系
4. 治理工作台:一站式治理平台
数据治理的概况和解法
腾讯 PCG 内容与平台事业群,包括大家所熟知的 QQ、腾讯视频、腾讯新闻、阅文集团,以及腾讯音乐等业务。在没有治理平台之前,数据治理是运动式的,有两个比较大的难点:
- 数据量大且复杂。每天大概有万亿级别的数据增量,而且数据的格式多样化,覆盖文本、图文、长短视频与语音等各种结构化、非结构化数据。
- 数据技术架构复杂。腾讯内部有多个业务,每个业务又有很多产品线,每个产品线用的技术架构又不尽相同。调度系统有用 Venus 的,也有用 US 的;数据治理脚本开发有用 pySQL 或 pySpark 的,也有用 Hive 的,还有用内部 SQL 脚本的。
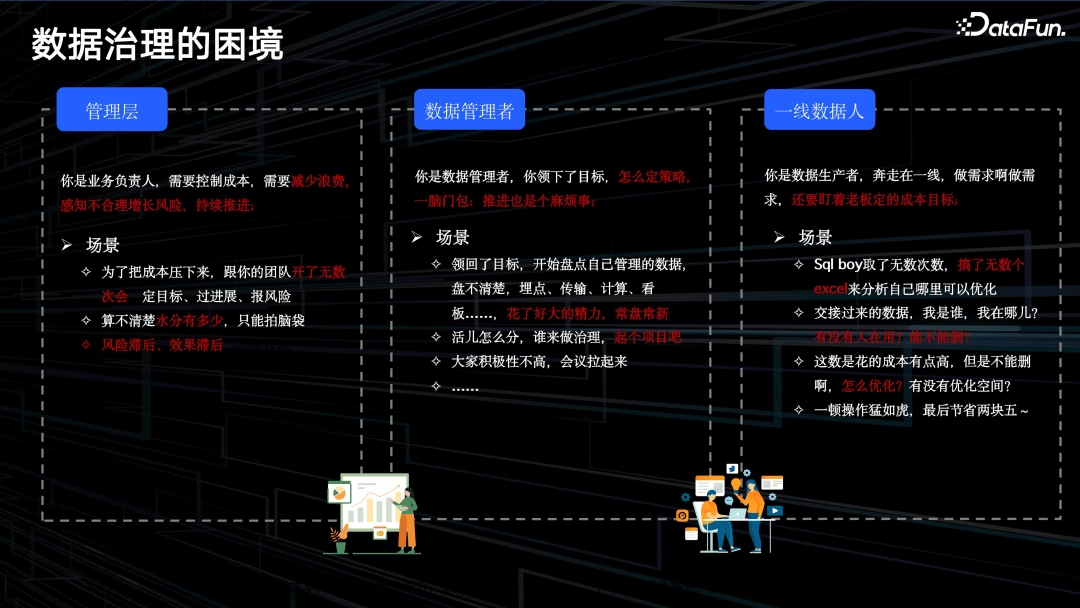
数据治理的困境,可以从面向的不同用户的不同场景来看:
- 管理层。作为业务负责人,需要控制成本、减少浪费,需要持续关注成本的变化,对未来做预估。为了把成本压下来,需要跟团队开很多次会议,定目标、过进展、报风险。但由于缺乏数据的深度治理和挖掘,以及数据治理平台,对数据治理任务的选择,难易、风险评估等,缺少定性、定量的方法。
- 数据管理者。作为一线数据 leader,定下了目标,怎么定策略、如何推进,也有难度。对于数据治理的整体链路,各个结点(如埋点、传输、计算等)的情况,也缺少及时准确的信息。数据治理任务推进困难。
- 一线数据人。作为数据生产者,每天需求已经很多了,还要关注老板定的成本目标。不断地分析哪里可优化,性能满不满足要求,如何优化。简单的治理可以做,复杂的涉及面广的就难以实施。
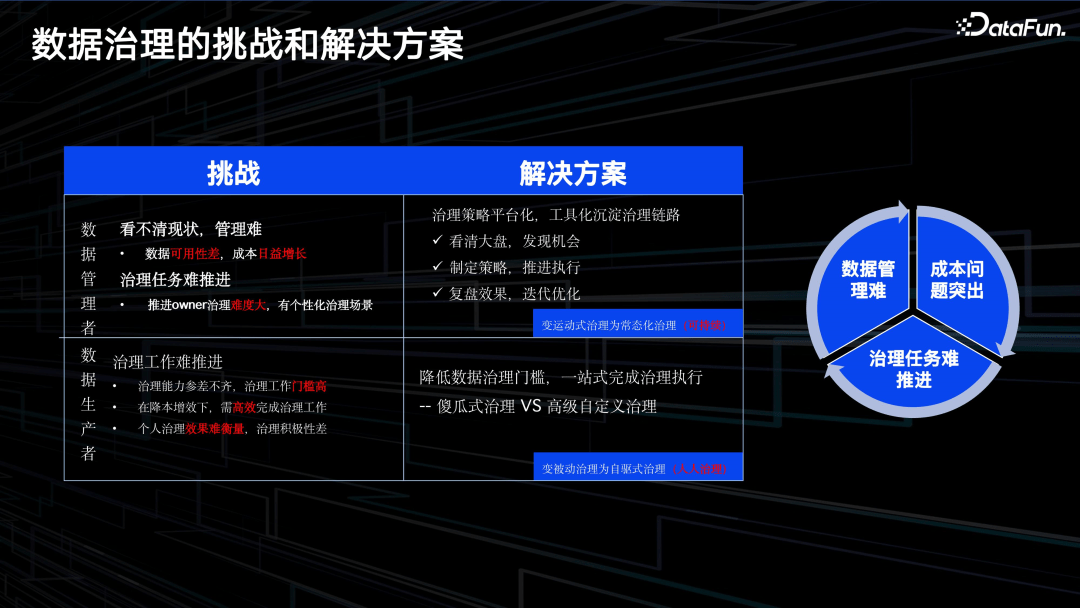
综上,原数据治理多为运动式、脉冲式的,成本高、效率低,需要新的数据治理解决方案,优化数据治理任务。
对于管理者,数据可用性差,成本日益增长,治理任务难推进。我们希望通过提供一套整体的解决方案,把一些日常的治理策略平台化和工具化,将经验沉淀下来。具体来说,提供三个功能:
- 帮助管理者看清楚大盘,了解资源利用率,发现治理机会;
- 辅助管理者去制定治理策略,并向相关人员推送,推进执行;
- 对数据治理的效果进行复盘,并辅助管理者推进迭代和优化,将运动式治理变成常态化治理。
对于数据生产者,数据治理推进难有三个原因:
- 治理能力参差不齐,治理门槛相对较高;
- 降本提效背景下,需要高效完成治理;
- 个人治理效果难衡量,治理积极性差。
我们为数据生产者提供平台,以降低数据治理门槛,一站式完成治理执行。例如对于某表,生命周期是 180 天,但我们发现,该表只用到最近 7 天,大部分时间都是浪费的,那么可以一键推送治理,修改生命周期,降低存储。对于某些做备份的任务,通过提供一系列和各个系统交互的接口,可以一键完成数据备份,从而降低数据治理的门槛。
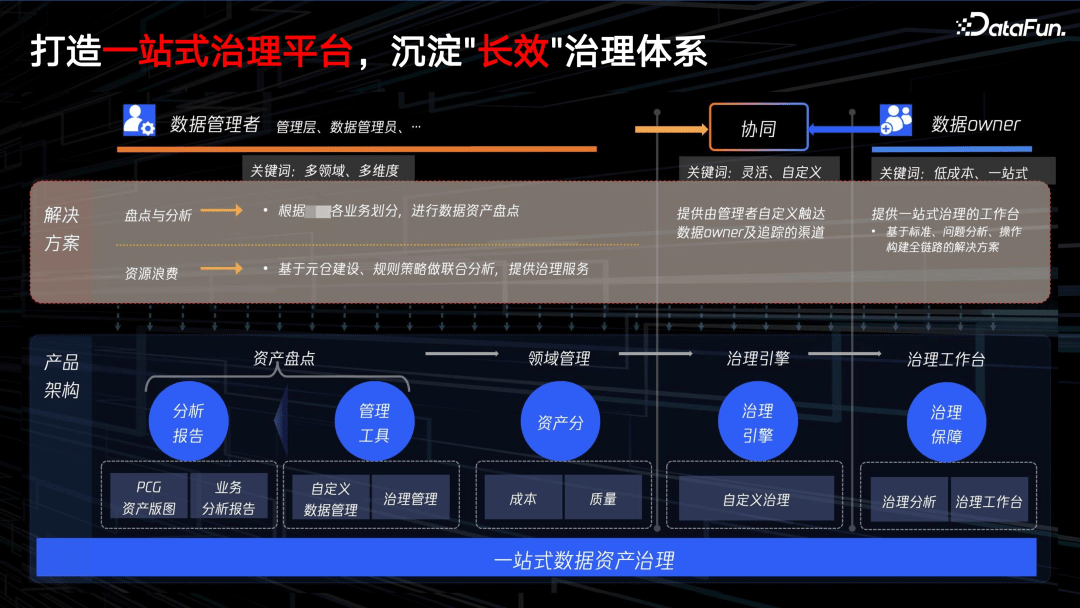
基于一站式数据治理平台,我们建立了一个“长效”治理的方法论体系。
从用户角色层看,支持数据管理者和数据 owner 两种用户角色。
对于数据管理者。我们为其提供多领域、多维度的视角,提供资产盘点和元仓建设两类解决方案。
- 资产盘点:比如通过对各组织的中间件、存储、队列等,提供各种维度下的资产详情,来帮助管理者看清楚资产的分布,进而辅助他进行下一步的治理。
- 基于元仓建设,我们抽象出很多治理策略来提供治理服务。
为支持资产盘点和元仓建设,从产品架构层,还抽象出了资产分,通过对用户下各类资产的打分和汇总,来代表用户所有资产的大致水平,资产分可以汇总到组织甚至业务 BG 粒度。资产分可以汇总用户资产的健康度、水位。
后面会介绍数据治理引擎,对所有资产不合理的地方进行抽象,得到一些治理项。这些治理项本身又是和资产分析挂钩的,如果资产项治理得好,资产分就会越来越高,如果长久不处理,那资产分可能会停止甚至会下降。通过资产分,管理者更易定KPI,也方便执行。
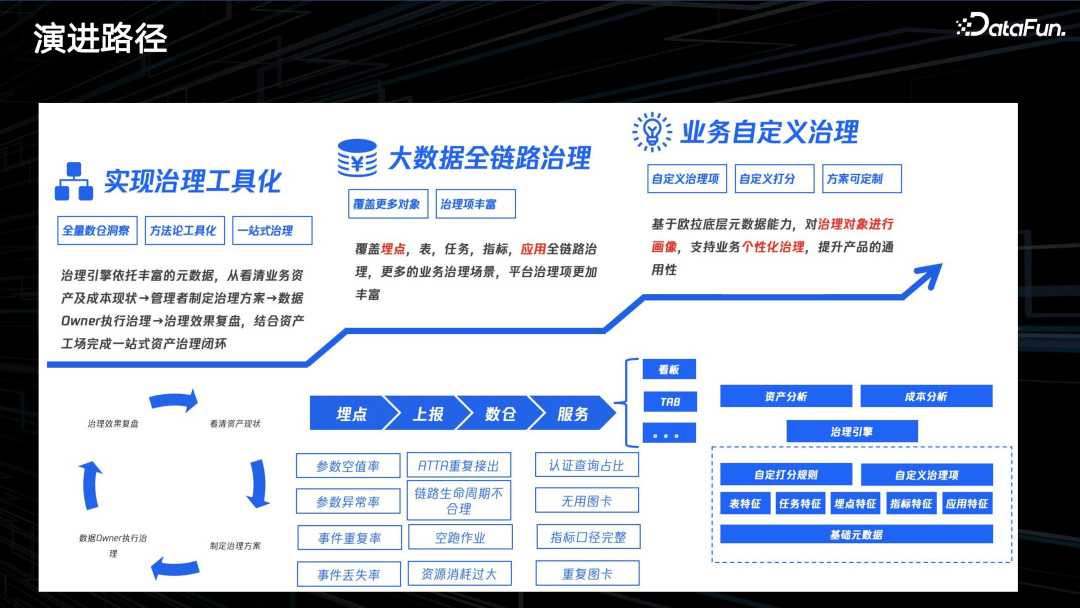
如上图,数据治理平台整体产品架构的演进过程,包括三个步骤:
- 第一步,实现治理工具化。比如,先盘点所有离线表资产情况,然后生成治理项并制定治理方案,再将方案发给数据 owner 进行执行,最后对治理效果进行复盘,最后再重复这个流程。
- 第二步,大数据全链路治理。对于一些中间环节,第一步已成功,就可以对其它治理对象应用这个模式。我们最早做的数据表,后面对整个数据生产链路里面的每一个环节,包括埋点上报、数仓加工、对外服务整个流程里的中间节点,都按照这个模式进行治理。如,埋点这里的治理项包括:参数空值率、参数异常率、事件重复率、事件丢失率等,并最终形成资产分。
- 第三步,业务自定义治理。通过支持个性化治理,提升产品通用性。
以上对数据治理的现状、困难以及解决的路径进行了概要的介绍。接下来介绍实现数据治理的一些关键工作。
腾讯 PCG 元仓建设:专注特征挖掘、构建治理引擎基石
在元仓建设层,我们专注于特征挖掘,这里包括三个方面:
- 全链路的数据整合清洗
- 全链路的血缘构建
- 基于血缘数据的治理特征挖掘
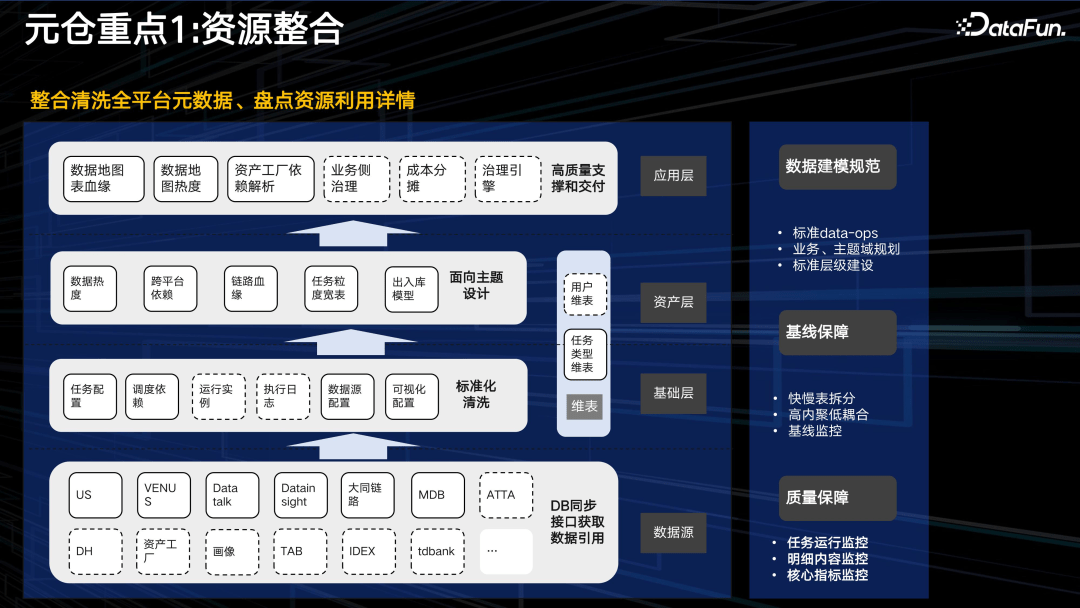
1. 资源整合
如上图,资源整合自下而上,依次包括数据源、基础层、资产层、应用层。
数据源层:包括任务调度平台 US 和 VENUS、报表平台 data talk 和 data insight、以及一些数据链路加工平台、业务数据库,以及实验信息、临时查询等生产工具。为了保证数据准确和及时,大多数据是近实时的,通过消息队列获取,离线也每天同步并进行整合。
基础层:获取所有数据后,会进行标准化治理。
资产层:重点考虑数据热度以及数据间的依赖关系,包括数据链路血缘、任务间依赖、宽表、出入库模型等。
应用层:最后通过应用层,实现数据的高质量交付。这里,一方面,需要全面梳理以发现数据治理的机会和价值。另一方面,也要保证整体产出的时效性以及质量。
应用层有个重点是成本分摊,即对每个细粒度的资源,都和成本进行关联。如一个表等,我们可以知道它的存储成本、计算成本。任何一种资源包括队列、埋点、上报等,都和成本关联,就可以清楚地知道,进行数据治理,可以带来多少成本收益。
2. 全链路实时血缘
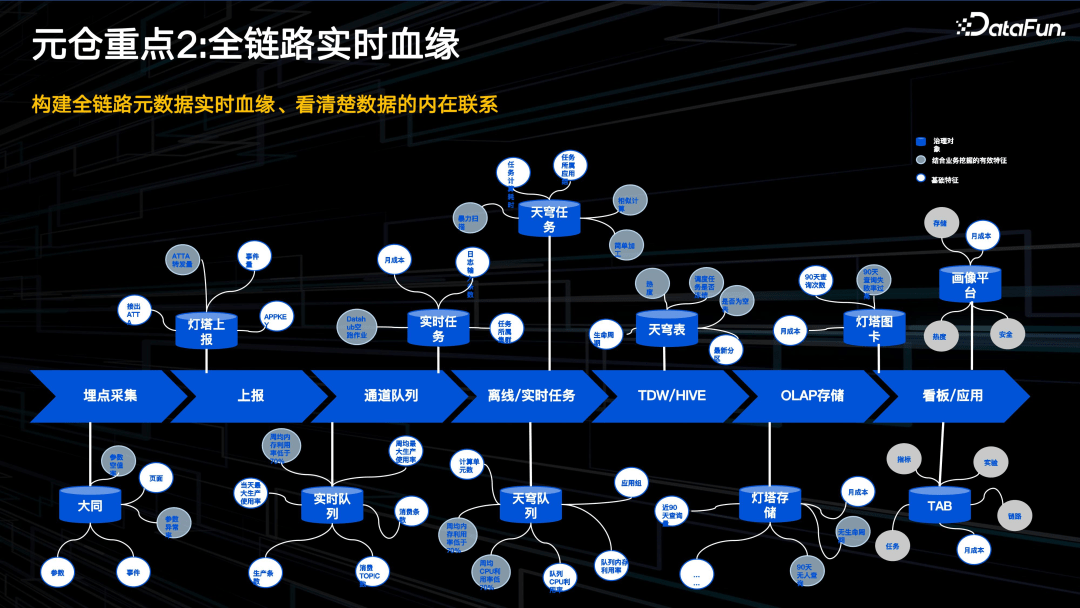
上图表示了大部分数据的加工流程:从前端埋点到上报,经过消息队列,离线、实时加工任务,到最终展现。我们对整个过程方案中所有的中间件实体进行抽象,挖掘出实体关联的可治理属性,包括成本、用量等,形成一个大图。
形成血缘大图后,通过图算法,可以做很多工作。比如,发现无用的数据看板,并顺着图,发现看板上游无用的节点,一直往前走,直到埋点上报表层。这样就可以一起处理,节省成本。
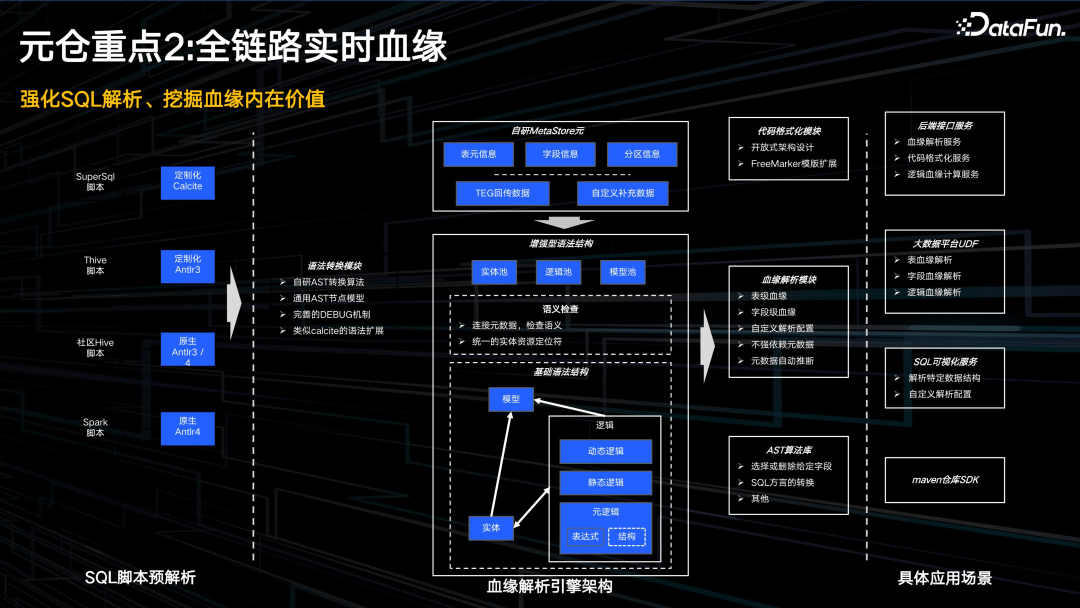
数据治理平台的血缘解析模型,也就是 SQL 解析模块。支持 4 种脚本类型:
- SuperSQL,腾讯内部的查询语句,屏蔽了多种常用 SQL 之间的差异性,使用 Calcite 定制解析;
- Thive,为了解决早期版本的性能问题内部定制的 Hive 版本,定制化 Antlr3 解析;
- Hive,原生 Antlr3/4 解析;
- Spark 脚本,主要指 Spark SQL,Antlr4 解析。
我们通过血缘解析引擎,定义了增强型的语法结构,屏蔽不同 SQL 脚本的差异性,对外提供统一视图。
其中,基础语法结构,包括实体、逻辑、模型三部分。
- 实体,是指 SQL 读了哪些表,有哪些字段;
- 逻辑,是指表之间是如何关联,字段如何筛选,加工逻辑是什么,以及针对 UDF 定义的关系;
- 模型,主要是从语义层面分析,这个 SQL 是干什么的。
有了上面的语法结构,就能够做一些深层次的特征挖掘。如两个 SQL 是否相似,只是一个比另一个多几个字段;或者某个表,很多字段下游根本没有引用,那么可以做冷字段处理。
血缘解析模块支持表级和字段级血缘解析,也可以自定义解析配置。用户可以使用一些接口,根据提供的模型,直接解析所需内容。我们也提供了协议解析模块的SDK,可以从 maven 库引入使用。
3. 治理特征挖掘
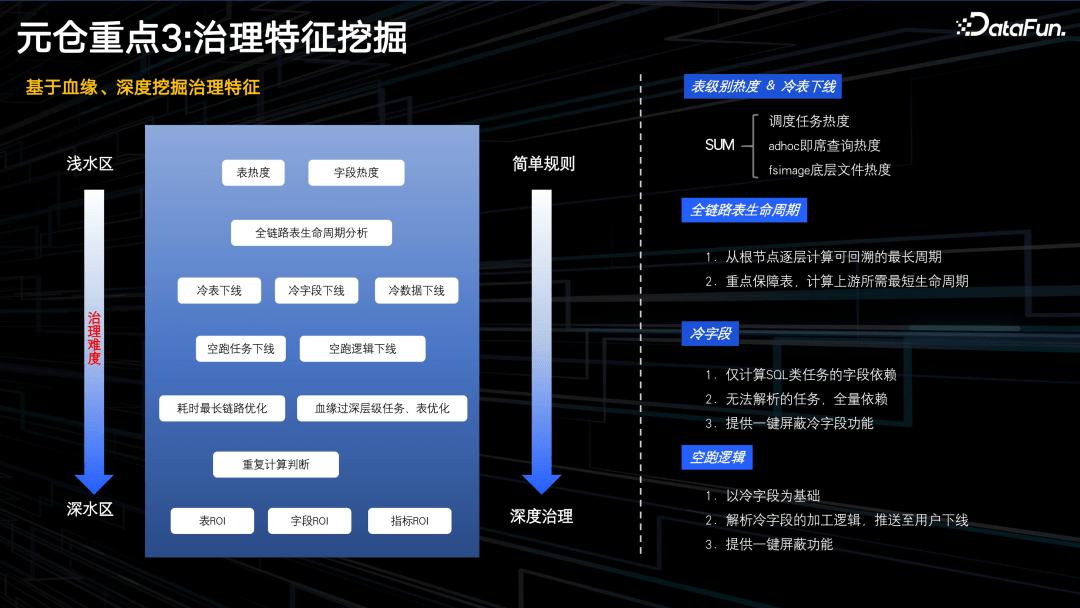
元仓建设中最关键的是挖掘治理特征,但治理特征和治理项之间有一定的 gap。
下面,我们从简单的治理项讲起,根据特征通过简单的规则就可以实现治理。例如:
- 表热度。可以用三种不同的原数据,一是查看表是否被任务调度系统的任务使用;二是这个表有没有被临时查询,是否经常被使用;三是扫描表底层文件的读取,是否被使用。通过这些数据,计算出表热度,并根据表热度生成一系列的治理项。
- 字段热度。同样的,根据血缘模块直接生成。
更复杂的一些挖掘特征,可能需图算法来处理。比如重复计算,如何判断两个 SQL 相似?通过血缘分析,也可以发现跨层依赖、穿透等违反开发规范的情况。
在这一章节中,我们通过元仓建设和血缘分析,发现一些治理特征,为进一步形成治理项提供了基础。
资产分体系:开放、可持续迭代的资产分体系
1. 资产分-衡量数据资产健康度的核心指标
下面介绍资产分体系,从五个维度对所有资产进行细粒度的刻画。
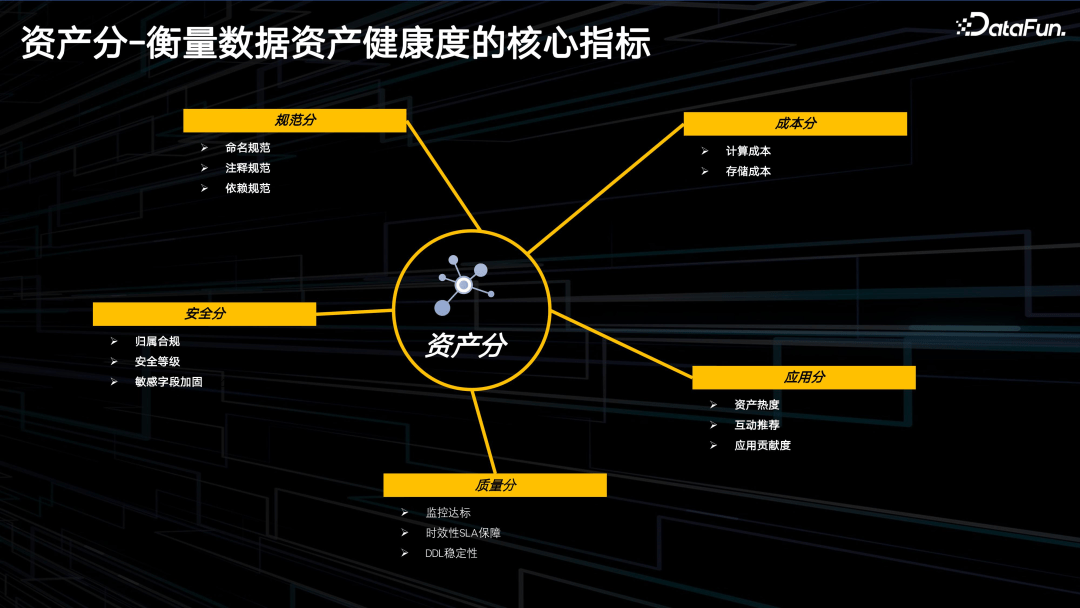
- 规范分。包括命名规范:是否遵循标准的市场分层,是否有业务语义等;注释规范;依赖规范等。
- 成本分。包括计算成本和存储成本。
- 安全分。包括归属合规:是否存在有离职或者转岗的同学,或者权限不合格的情况;安全等级;敏感字段加固:有没有敏感字段直接是裸数据。
- 质量分。
- 应用分。
通过这 5 个维度可以看出,资产分,不仅考虑了成本,也考虑了规范和安全方面情况。
2. 特征工程&扣分规则

资产分基于扣分规则来生成。使用的特征包括前面几个维度的一些细则,比如:安全字段没有加固,扣 10 分;表注释不规范,扣几分。对每个维度,不同特征的治理项都做了扣分,汇总后,分数越高,说明资产的质量越高。若分数较低,就需要推动去做治理。
3. 引入规则引擎、低 ETL 代码
如何根据特征生成治理项,并最终生成资产分?这里依赖特征中间层以及生成治理项的规则引擎。
针对特征,我们构建了标准化结构化的治理中间层,包括对象、维度、特征三个要素。其中,特征有两类:
- 直接特征:经过复杂算法加工出来的定性的结论。如是否存在跨层依赖,是否重复计算;
- 间接特征:可供进一步挖掘的特征。比如:近 XX 天无人访问,队列使用率 X% 等。

特征和治理项之间还有 gap。比如说近多少天无人,近 3 天无人访问,这是个特征,但它不一定是个治理项。有的业务近一天不访问,就需要治理,有的业务 90 天没人访问也无所谓,不需处理。再比如队列使用率 80% 就一定治理吗?不一定。
所以,需要把特征转化成治理项。可以通过引入规则引擎,采用界面的方法,生成一些业务自定义的治理项。
- 通过将各治理项归属到资产分的五个分类里,可以得出整个资产分的值。
- 通过标准化治理分层,利用中间层,将产品方案和前端元数据解耦;也就是对于其它公司,若已有元仓,只需要将这些特征灌到治理中间层,不需任何改动,就可以直接生成一套数据。
4. 治理引擎数据全流程
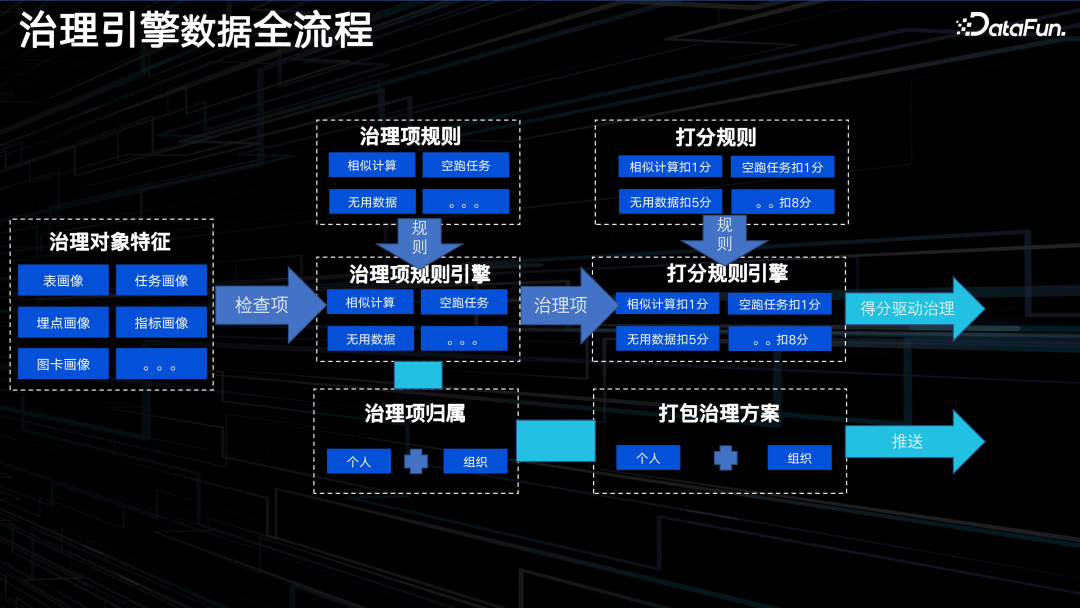
上图展示了治理引擎数据的全流程。
首先,治理项规则引擎接收治理对象的特征和一些定性结论,根据配置文件,将这些特征识别成治理项;然后,打分规则引擎根据治理项打分,根据另外一个配置文件,计算出在各分类下分值;最后,将这个分值推送给用户,同时治理项的明细和个人及组织绑定,打包成治理方案推送给管理者及一线数据 owner。
治理工作台:一站式治理平台
下面,我们介绍一下一站式治理平台的具体实现,主要包括以下功能:
1. 看清业务资产及成本现状
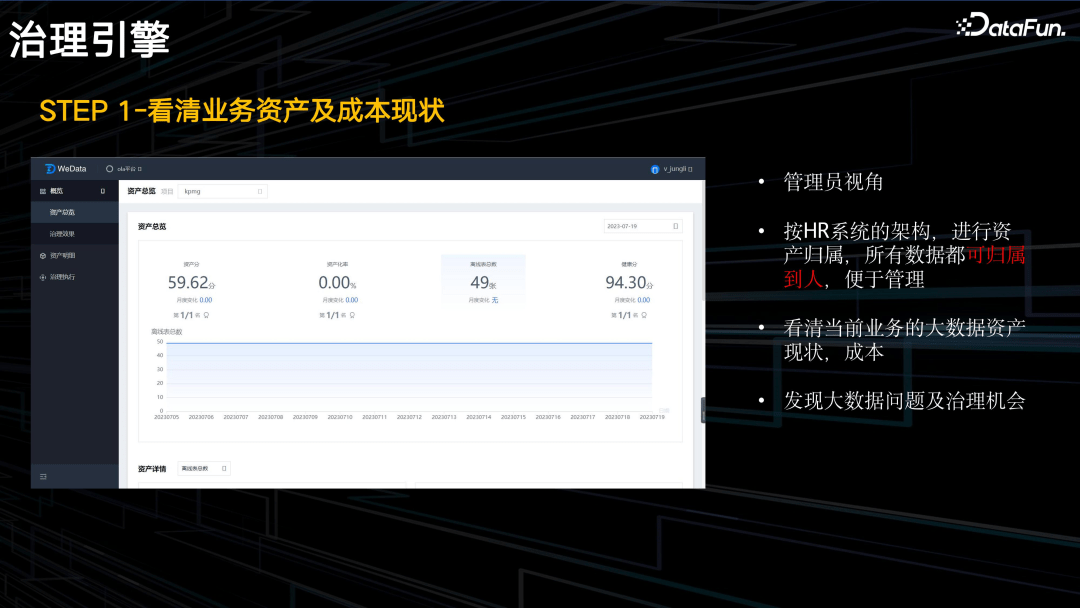 从管理员的视角,按 HR 系统的架构,进行资产归属,将所有数据归属到个人,方便管理。并看清当前业务的资产现状,资产分,资产率,以及资源的明细。通过这些,来帮助管理层发现大数据的问题及治理机会。
从管理员的视角,按 HR 系统的架构,进行资产归属,将所有数据归属到个人,方便管理。并看清当前业务的资产现状,资产分,资产率,以及资源的明细。通过这些,来帮助管理层发现大数据的问题及治理机会。
2. 管理者制定治理方案
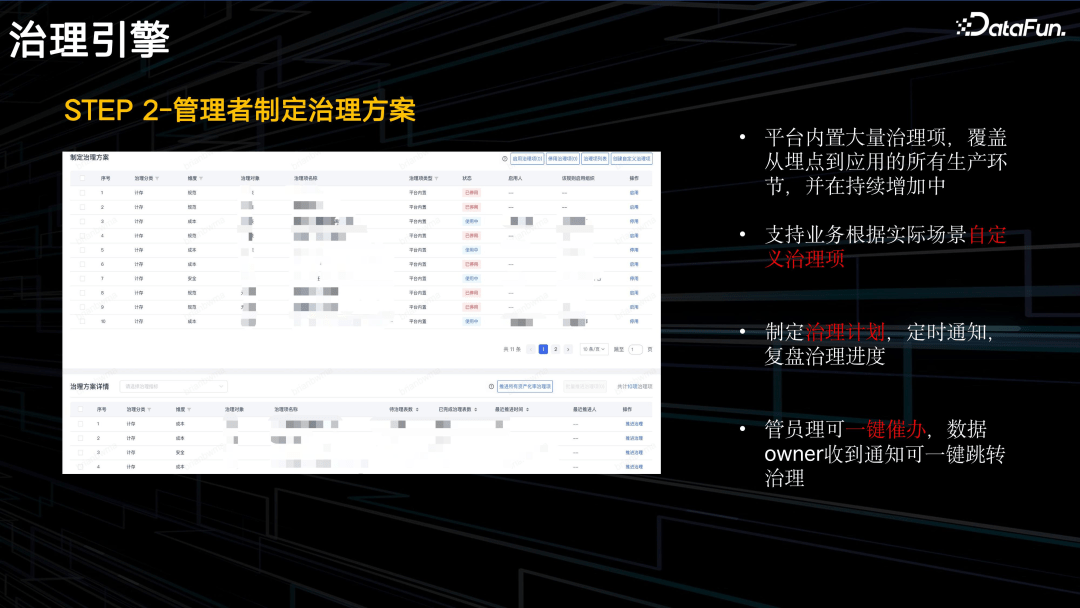
平台内置了 100+ 治理项,覆盖从埋点到应用的整个环节,并可以根据不同的粒度自定义治理项,定制治理方案。管理者可一键催办,让一线的数据 owner 去执行对应的治理方案。
3. 数据 Owner 执行治理
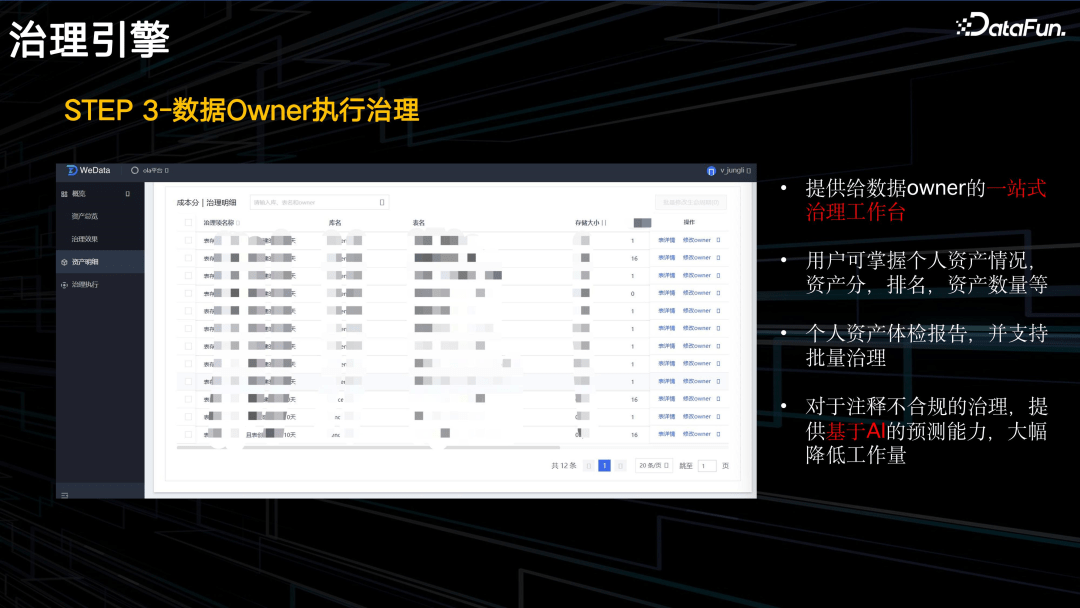
平台为数据 owner 提供一站式的治理工作台,对于一些基本操作,比如删表等,提供一键性的操作。用户,不仅包括数据开发者,也包括运营或产品同学,都可以看到自己的数据资产明细,包括资产分、排名、数量等。
4. 治理效果复盘
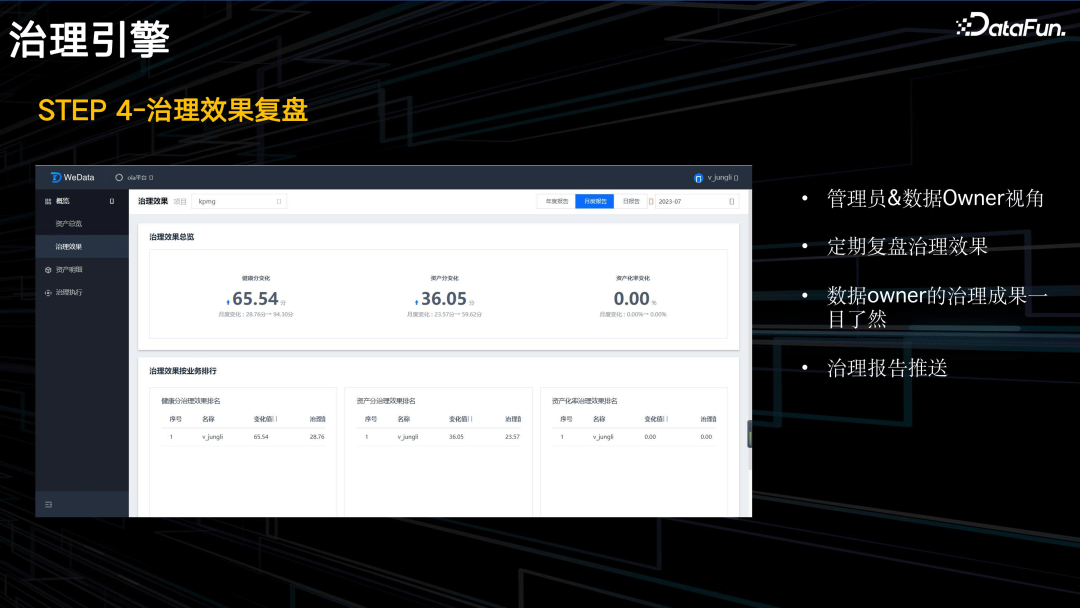
无论是管理者还是数据 Owner,通过平台可以了解一段时间的治理效果,成本节省了多少,资产分提升了多少。每个月都会向组织和个人推送治理报告。
以上就是本次分享的内容,谢谢大家。
版权声明及安全提醒:本文转自网络平台,文章仅代表作者观点,不代表「金融文库」立场。相关版权归原作者所有,「金融文库」仅提供免费交流与学习,相关内容与材料请勿用于商业。我们感谢每一位原创作者的辛苦付出与创作,如本转载内容涉及版权及侵权问题,请及时联系我们客服处理(微信号:JRwenku8),谢谢!


