一、 什么是用户画像
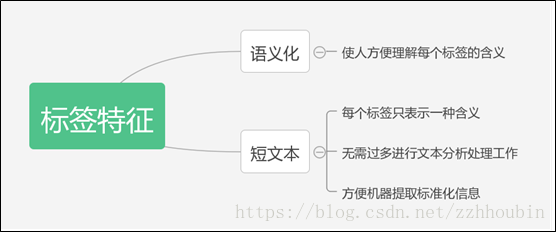
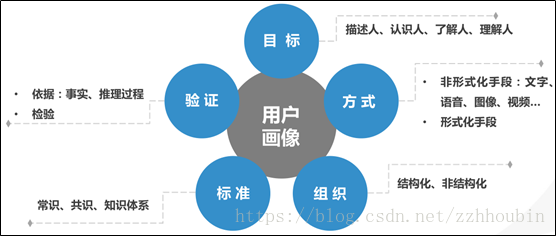
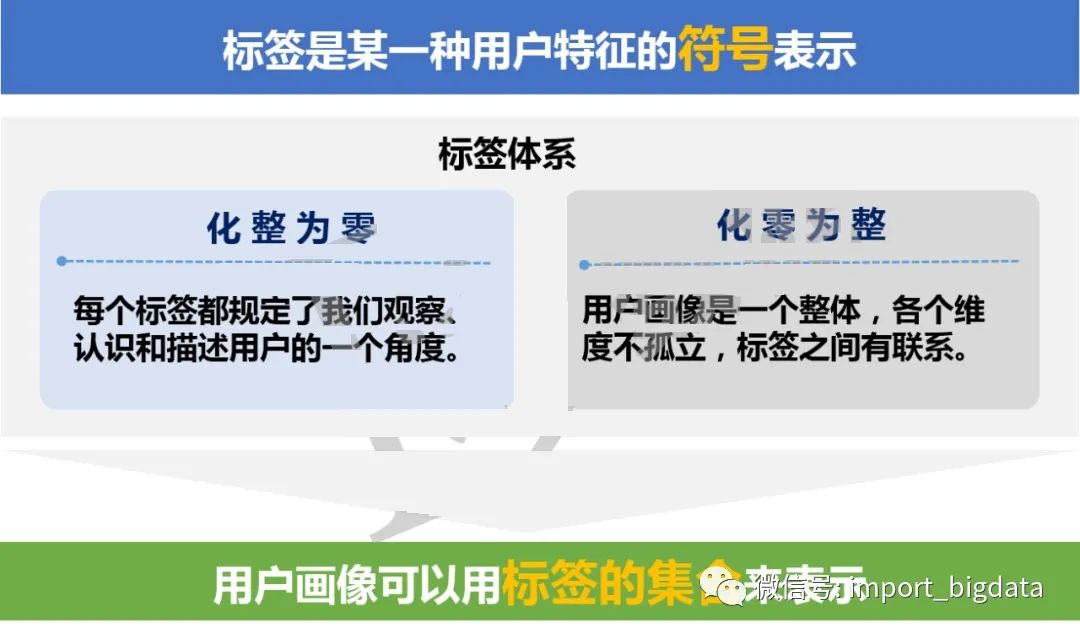
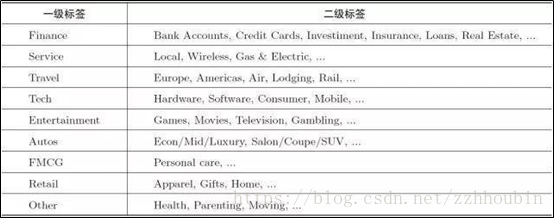
二、用户标签的分类
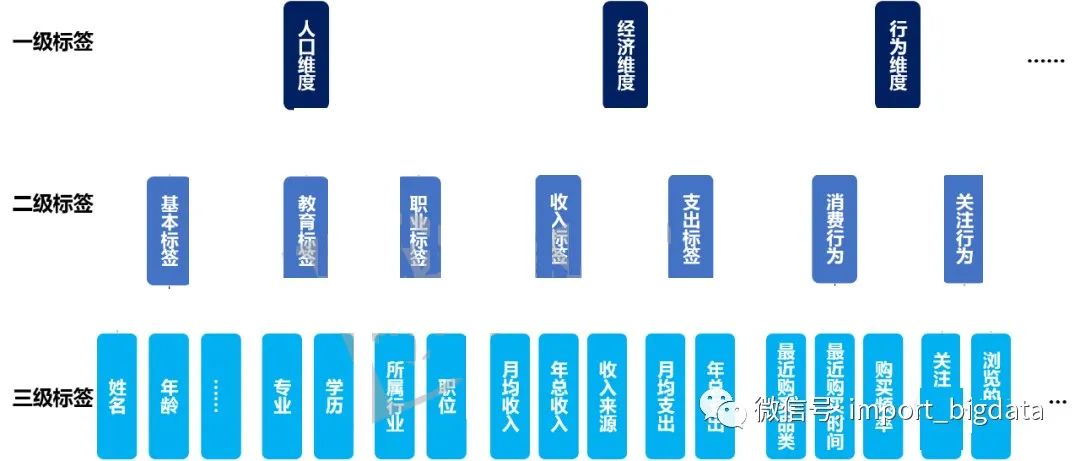
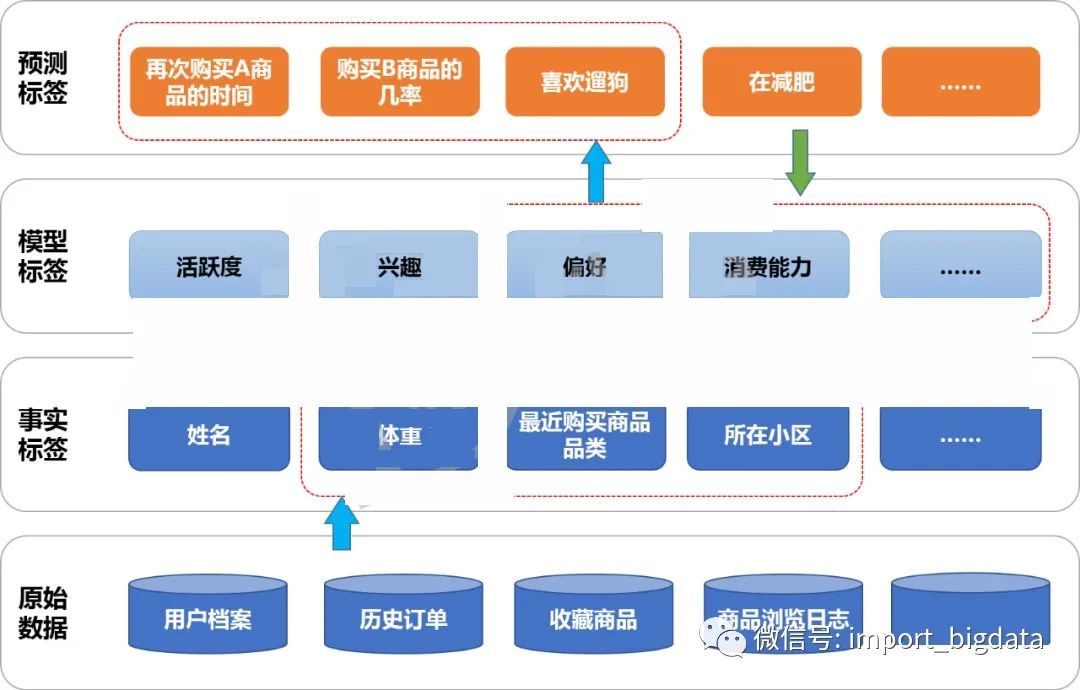
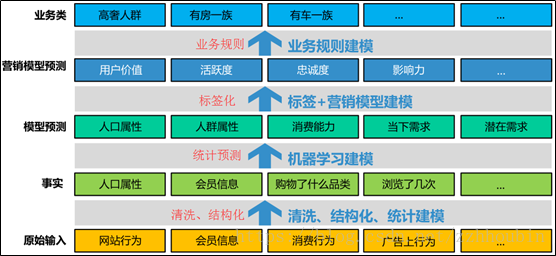
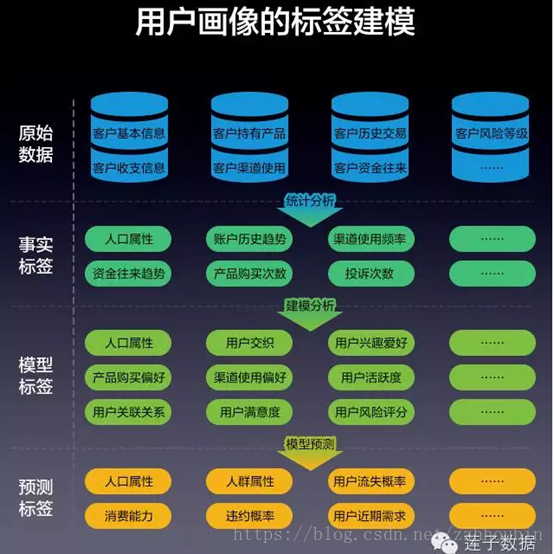
三、用户画像标签体系的建立
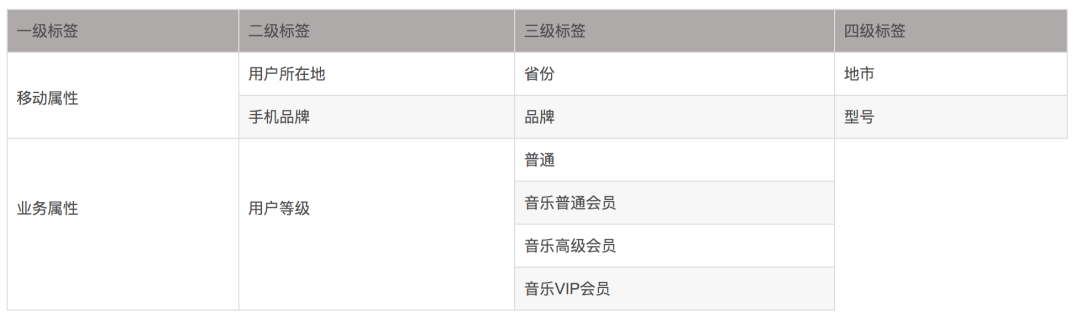

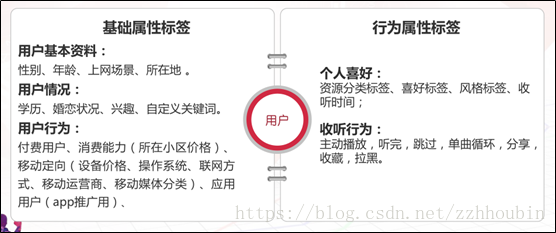

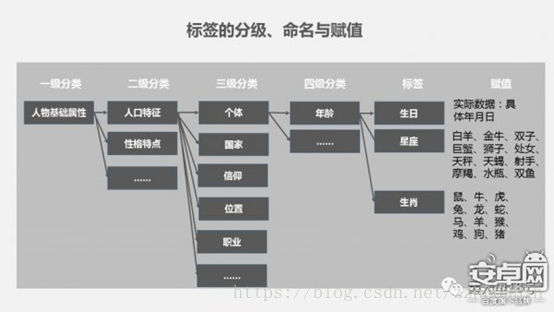

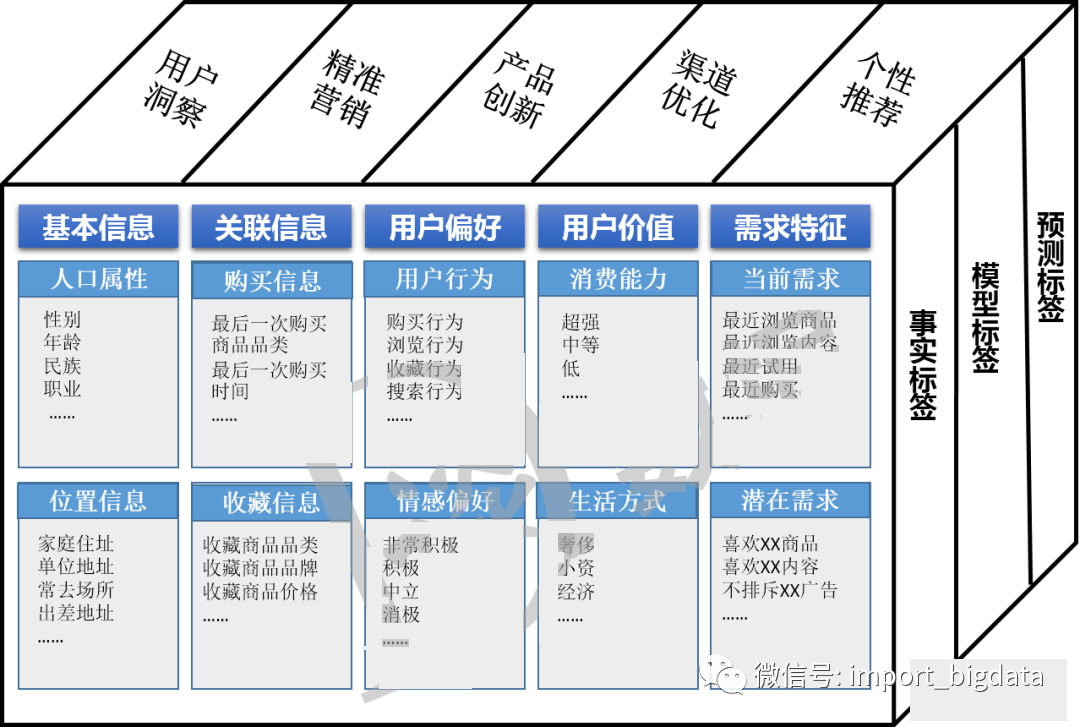
五、用户画像的应用场景
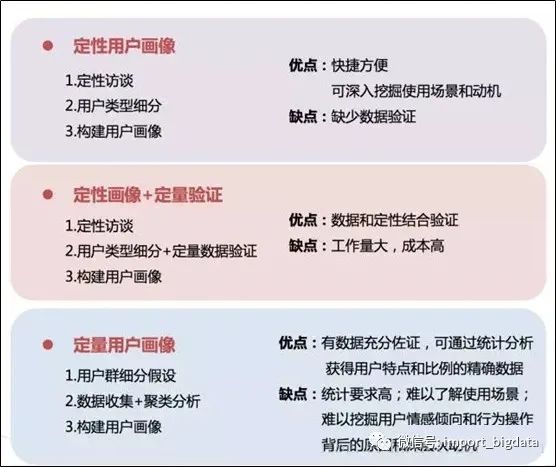
六、用户画像的分类
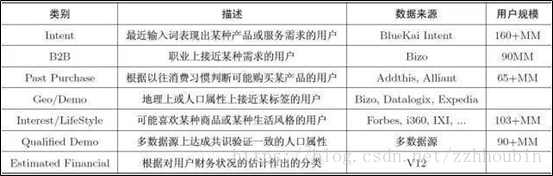
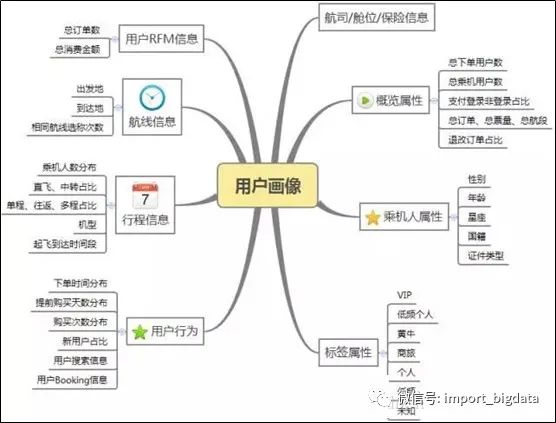
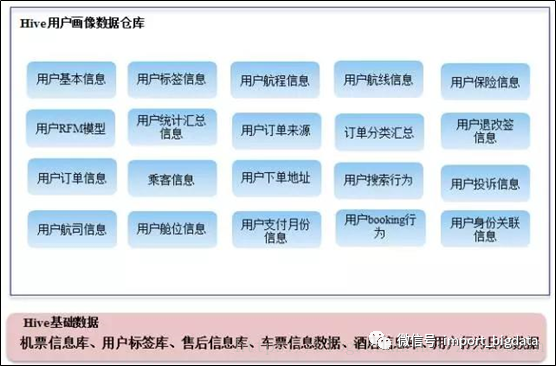
七、用户画像需要用到哪些数据
(2)兴趣特征:浏览内容、收藏内容、阅读咨询、购买物品偏好等
(3)消费特征:与消费相关的特征
(4)位置特征:用户所处城市、所处居住区域、用户移动轨迹等
(5)设备属性:使用的终端特征等
(6)行为数据:访问时间、浏览路径等用户在网站的行为日志数据
(7)社交数据:用户社交相关数据

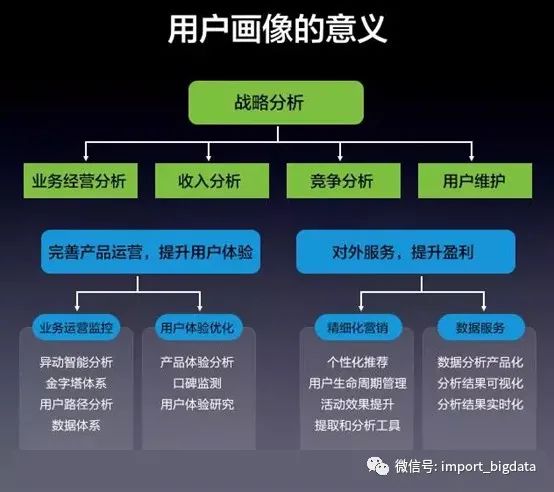
八、用户画像的作用
(2)用户统计:根据用户的属性、行为特征对用户进行分类后,统计不同特征下的用户数量、分布;分析不同用户画像群体的分布特征。
(3)数据挖掘:以用户画像为基础构建推荐系统、搜索引擎、广告投放系统,提升服务精准度。
(4)服务产品:对产品进行用户画像,对产品进行受众分析,更透彻地理解用户使用产品的心理动机和行为习惯,完善产品运营,提升服务质量。
(5)行业报告&用户研究:通过用户画像分析可以了解行业动态,比如人群消费习惯、消费偏好分析、不同地域品类消费差异分析
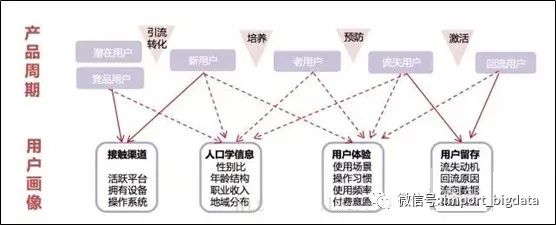
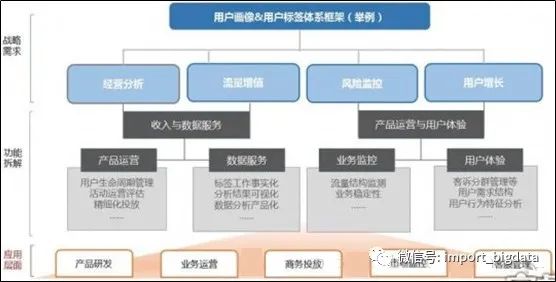
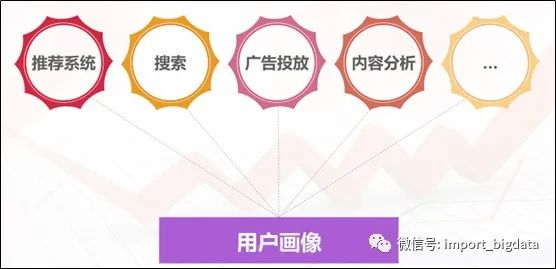
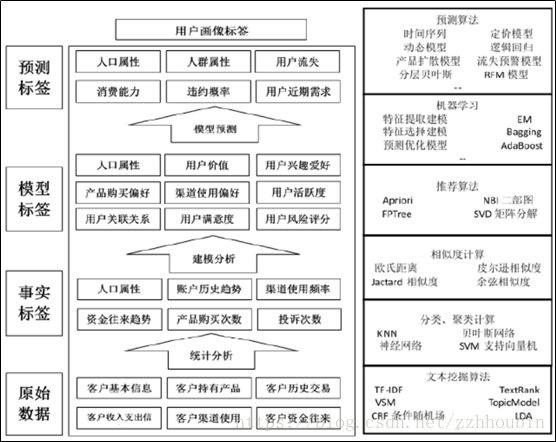
九、用户画像的体系架构
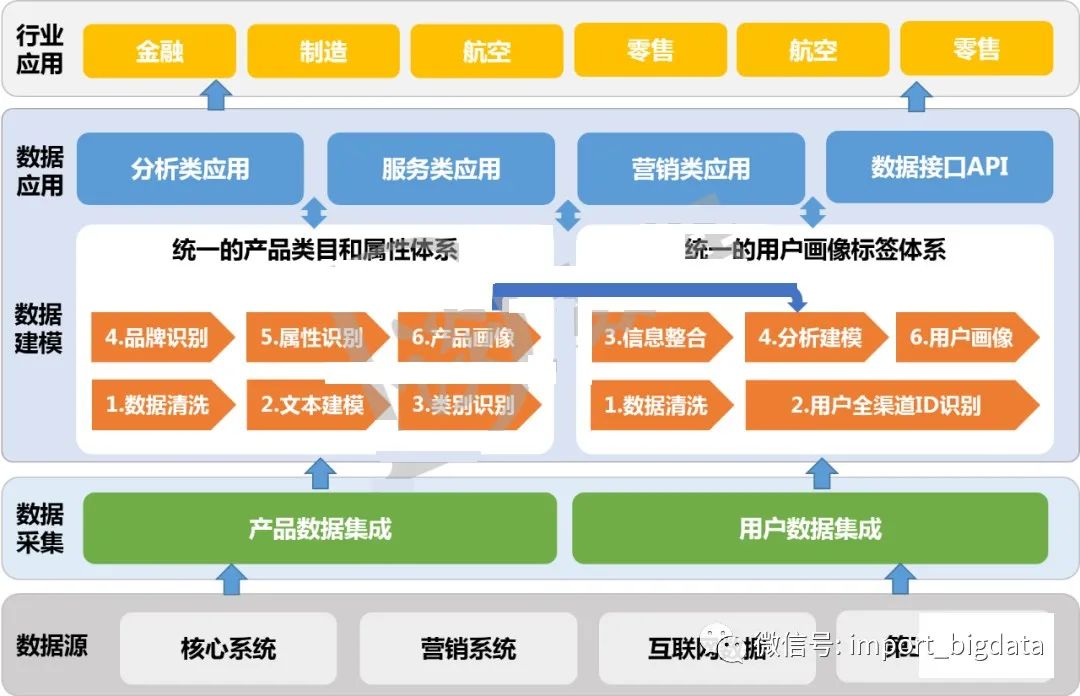
十、用户画像的建设步骤
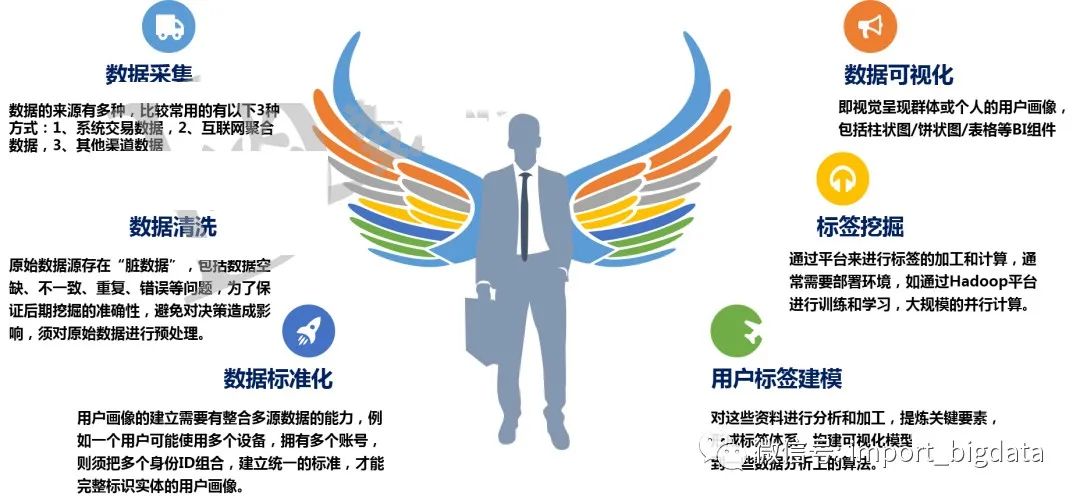

十一、 用户画像平台&架构
用户画像平台需要实现的功能。
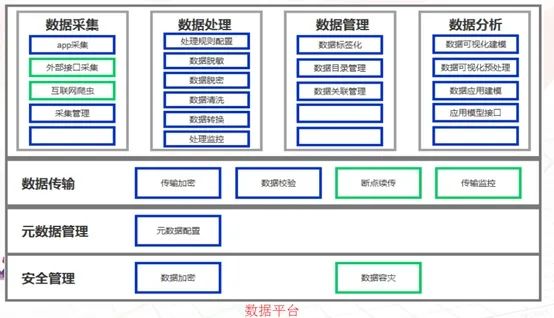
用户画像系统技术架构
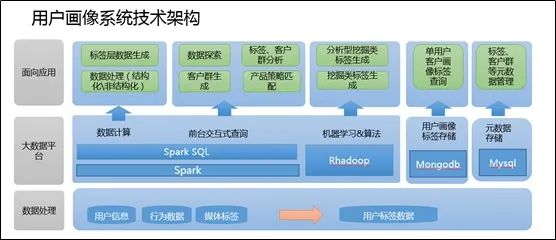
1、数据处理
a、数据指标的梳理来源于各个系统日常积累的日志记录系统,通过sqoop导入hdfs,也可以用代码来实现,比如spark的jdbc连接传统数据库进行数据的cache。还有一种方式,可以通过将数据写入本地文件,然后通过sparksql的load或者hive的export等方式导入HDFS。
b、通过hive编写UDF 或者hiveql根据业务逻辑拼接ETL,使用户对应上不同的用户标签数据(这里的指标可以理解为每个用户打上了相应的标签),生成相应的源表数据,以便于后续用户画像系统,通过不同的规则进行标签宽表的生成。
2、数据平台
a、数据平台应用的分布式文件系统为Hadoop的HDFS,因为Hadoop2.0以后,任何的大数据应用都可以通过ResoureManager申请资源,注册服务。比如(sparksubmit、hive)等等。而基于内存的计算框架的出现,就并不选用Hadoop的MapReduce了。当然很多离线处理的业务,很多人还是倾向于使用Hadoop,但是Hadoop封装的函数只有map和Reduce太过单一,而不像spark一类的计算框架有更多封装的函数(可参考博客spark专栏)。可以大大提升开发效率。
b、计算的框架选用Spark以及RHadoop,这里Spark的主要用途有两种,一种是对于数据处理与上层应用所指定的规则的数据筛选过滤,(通过Scala编写spark代码提交至sparksubmit)。一种是服务于上层应用的SparkSQL(通过启动spark thriftserver与前台应用进行连接)。RHadoop的应用主要在于对于标签数据的打分,比如利用协同过滤算法等各种推荐算法对数据进行各方面评分。
c、MongoDB内存数据的应用主要在于对于单个用户的实时的查询,也是通过对spark数据梳理后的标签宽表进行数据格式转换(json格式)导入mongodb,前台应用可通过连接mongodb进行数据转换,从而进行单个标签的展现。(当然也可将数据转换为Redis中的key value形式,导入Redis集群)
d、mysql的作用在于针对上层应用标签规则的存储,以及页面信息的展现。后台的数据宽表是与spark相关联,通过连接mysql随后cache元数据进行filter、select、map、reduce等对元数据信息的整理,再与真实存在于Hdfs的数据进行处理。
3、面向应用
从刚才的数据整理、数据平台的计算,都已经将服务于上层应用的标签大宽表生成。(用户所对应的各类标签信息)。那么前台根据业务逻辑,勾选不同的标签进行求和、剔除等操作,比如本月流量大于200M用户(标签)+本月消费超过100元用户(标签)进行和的操作,通过前台代码实现sql的拼接,进行客户数目的探索。这里就是通过jdbc的方式连接spark的thriftserver,通过集群进行HDFS上的大宽表的运算求count。(这里要注意一点,很多sql聚合函数以及多表关联join 相当于hadoop的mapreduce的shuffle,很容易造成内存溢出,相关参数调整可参考本博客spark栏目中的配置信息)这样便可以定位相应的客户数量,从而进行客户群、标签的分析,产品的策略匹配从而精准营销。
十二、用户画像困难点、用户画像瓶颈
困难点
用户画像困难点主要表现为以下4个方面
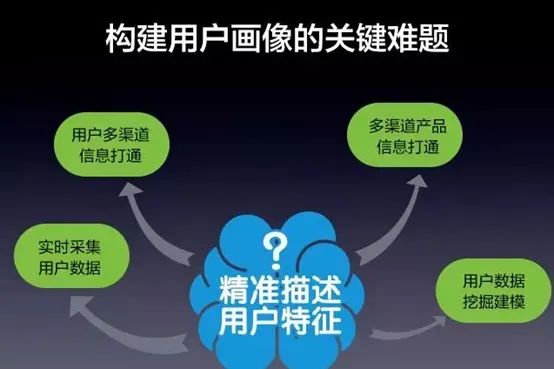
在画像之前需要知道产品的用户特征和用户使用产品的行为等因素,从而从总体上掌握对用户需求需求
创建用户画像不是抽离出典型进行单独标签化的过程,而是要融合边缘环境的相关信息来进行讨论
挑战
我们期间遇到了两方面的挑战:
1、亿级画像系统实践和应用
2、记录和存储亿级用户的画像,支持和扩展不断增加的维度和偏好,毫秒级的更新,支撑个公司性化推荐、广告投放和精细化营销等产品。
版权声明及安全提醒:本文转自网络平台,文章仅代表作者观点,不代表「金融文库」立场。相关版权归原作者所有,「金融文库」仅提供免费交流与学习,相关内容与材料请勿用于商业。我们感谢每一位原创作者的辛苦付出与创作,如本转载内容涉及版权及侵权问题,请及时联系我们客服处理(微信号:JRwenku8),谢谢!


