近几年,数字驱动的口号越喊越响,在这样一个用数据说话的时代,数据在一定程度上决定企业的业务和决策。而从数据驱动的方面考虑,多维实时数据分析系统的重要性也不言而喻。但是当数据量巨大的情况下,企业对数据技术也提出了更高的要求,但是要实现极低延迟的实时计算和亚秒级的多维实时查询还是有难度的。
以下内容根据其演讲整理:
01调研
-
推荐同学10分钟前上了一个推荐策略,想知道在不同人群的推荐效果怎么样? -
运营同学想知道,在广东省的用户中,最火的广东地域内容是哪些? -
审核同学想知道,过去5分钟,游戏类被举报最多的内容和账号是哪些? -
老板可能想了解,过去10分钟有多少用户在看点消费了内容?
02了解项目背景
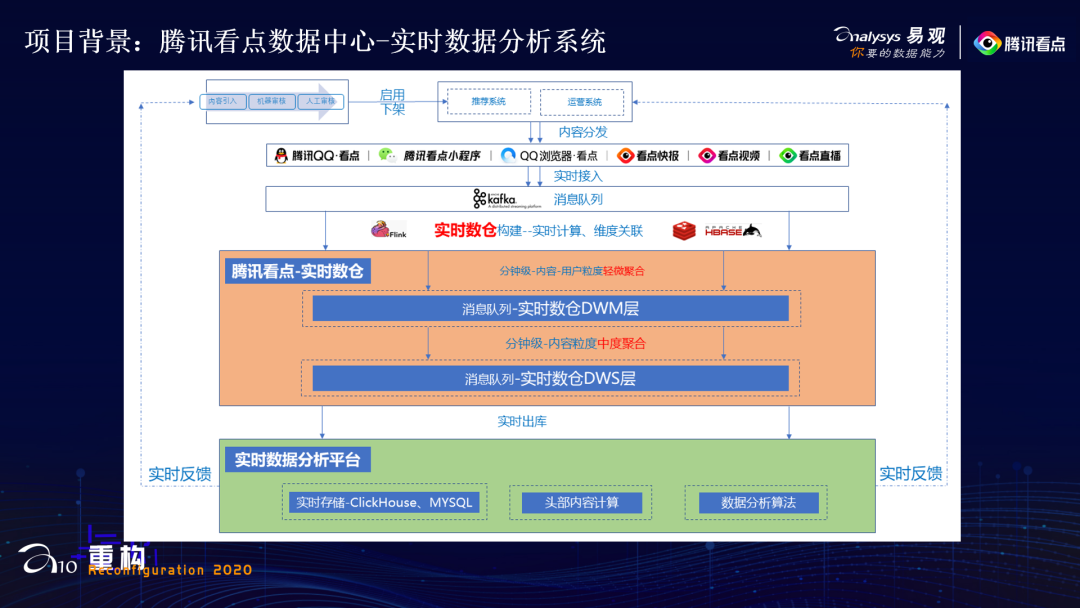
03方案选型
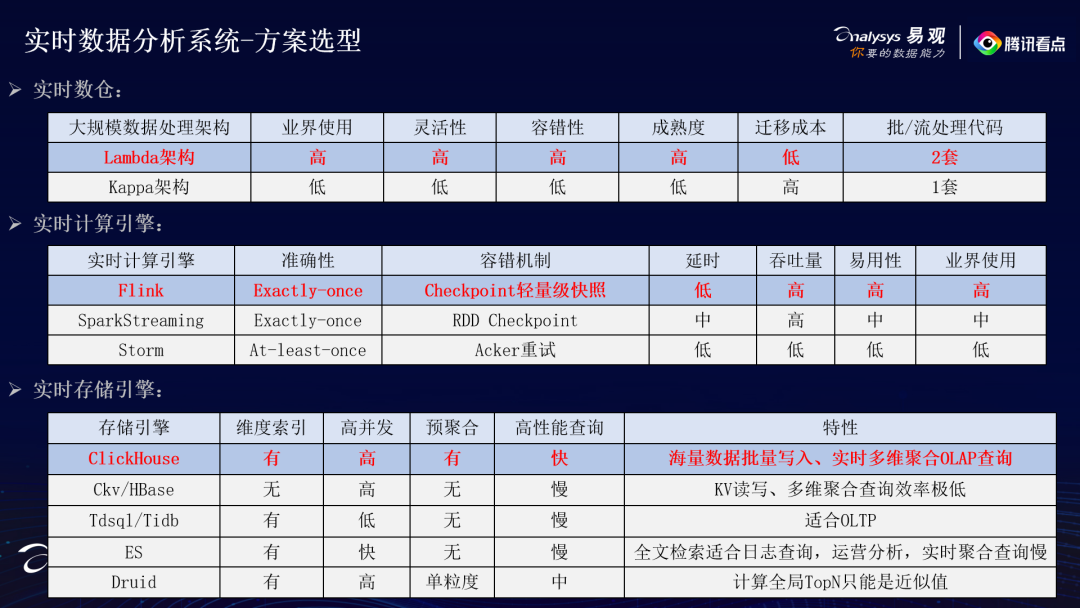
-
实时数仓的选型:腾讯看点选择了业界比较成熟的Lambda架构,Lambda架构具有灵活性高、容错性高、成熟度高和迁移成本低众多有点;缺点是实时、离线数据需要使用两套代码,可能业务逻辑修改了,但是批次没有跟上。腾讯看点对这个问题的处理方法是每天都进行数据对账工作,如果有异常则进行告警。 -
实时计算引擎选型:选择了Flink作为实时计算引擎。因为Flink设计之初就是为了流处理,此外,Flink还具有Exactly-once的准确性、轻量级Checkpoint容错机制、低延时高吞吐和易用性高的特点,是最佳选择。 -
实时存储引擎选型:腾讯看点的业务对维度索引、支持高并发、预聚合、高性能实时多维OLAP查询有要求,而Hbase、Tdsql和ES都不能满足。Druid存在按照时序划分Segment的缺陷,无法将同一个内容,存放在同一个Segment上,计算全局TopN只能是近似值。综合对比,最终选择了MPP数据库引擎ClickHouse。
04设计目标与设计难点分析
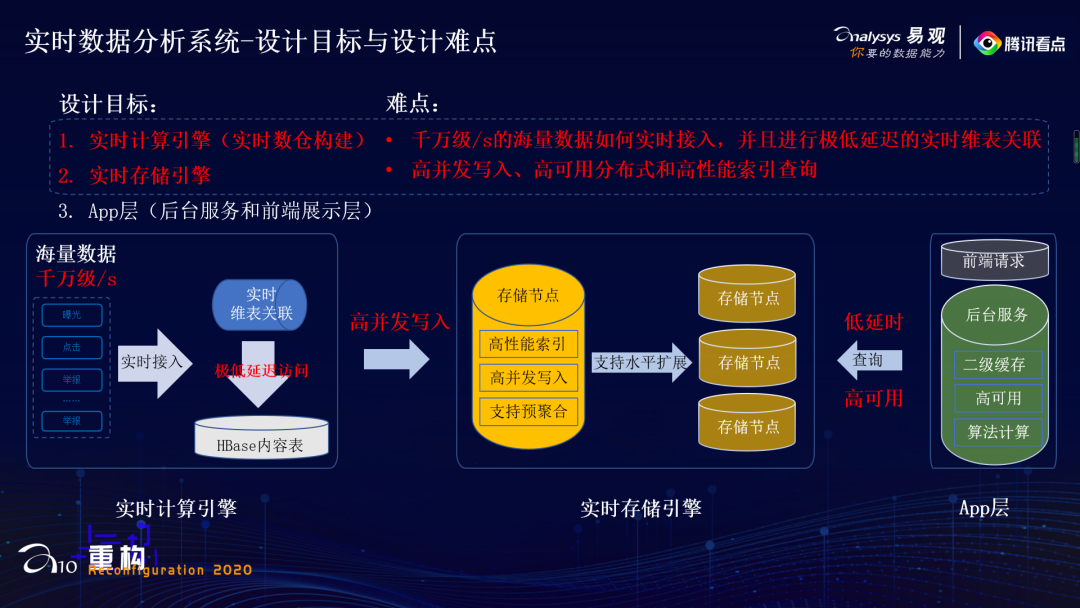
05难点攻克
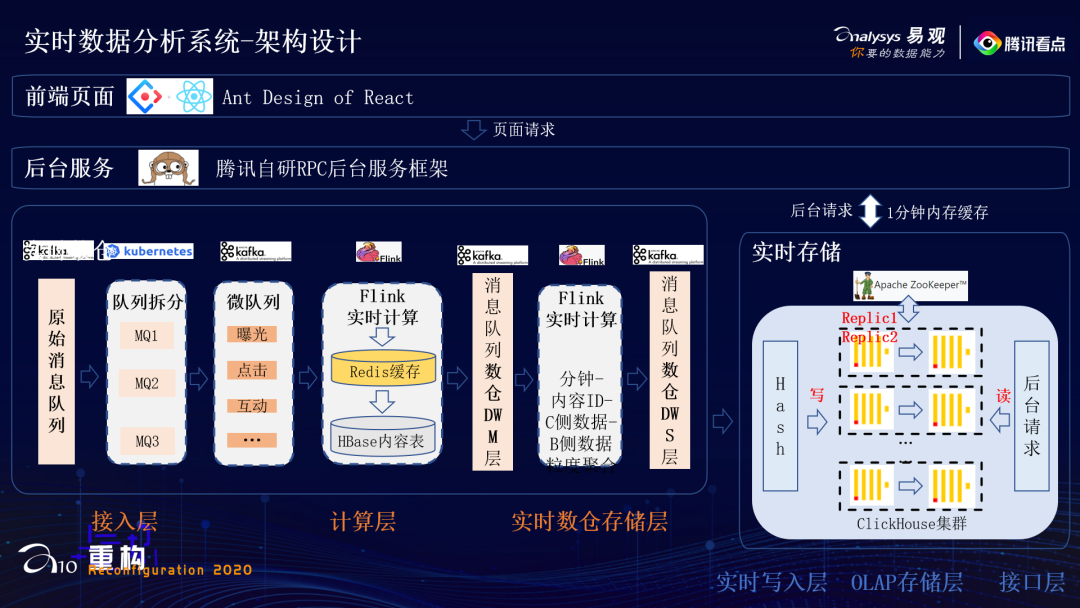
- 接入层主要是从千万级/s的原始消息队列中,拆分出不同行为数据的微队列,拿看点的视频来说,拆分过后,数据就只有百万级/s了;
-
实时计算层主要负责,多行行为流水数据进行行转列,实时关联用户画像数据和内容维度数据; -
实时数仓存储层主要是设计出符合看点业务的,下游好用的实时消息队列。我们暂时提供了两个消息队列,作为实时数仓的两层。一层DWM层是内容ID-用户ID粒度聚合的,就是一条数据包含内容ID-用户ID还有B侧内容数据、C侧用户数据和用户画像数据;另一层是DWS层,是内容ID粒度聚合的,一条数据包含内容ID,B侧数据和C侧数据。可以看到内容ID-用户ID粒度的消息队列流量进一步减小到十万级/s,内容ID粒度的更是万级/s,并且格式更加清晰,维度信息更加丰富。
- 实时写入层主要是负责Hash路由将数据写入;
- OLAP存储层利用MPP存储引擎,设计符合业务的索引和物化视图,高效存储海量数据;
- 后台接口层提供高效的多维实时查询接口。
-
第一个是,在Flink实时计算环节,先按照1分钟进行了窗口聚合,将窗口内多行行为数据转一行多列的数据格式,经过这一步操作,原本小时级的关联耗时下降到了十几分钟,但是还是不够的。
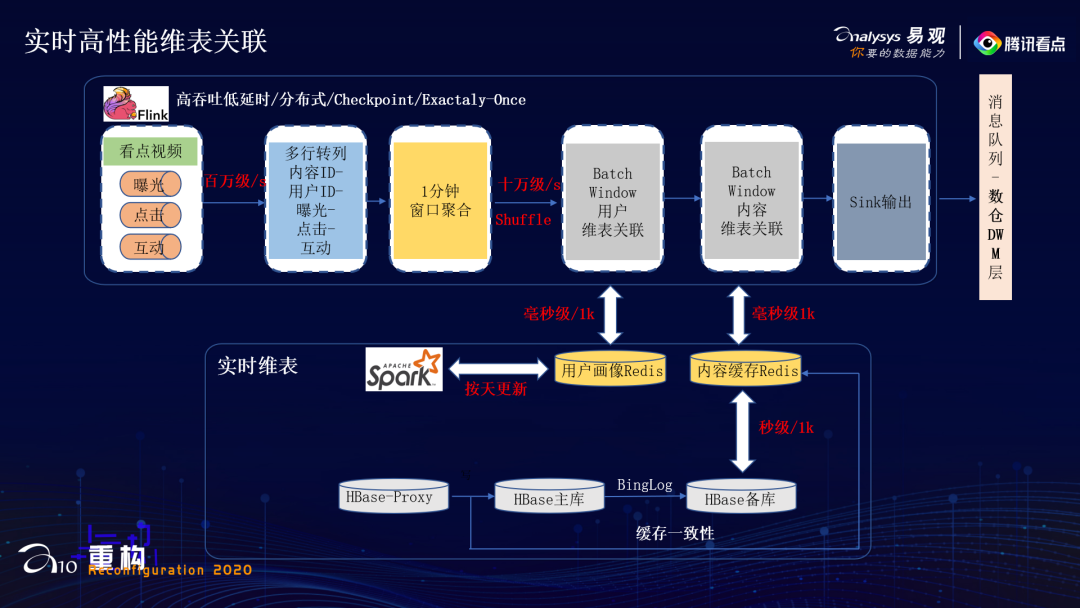
-
第二个是,在访问HBase内容之前设置一层Redis缓存,因为1000条数据访问HBase是秒级的,而访问Redis是毫秒级的,访问Redis的速度基本是访问HBase的1000倍。为了防止过期的数据浪费缓存,缓存过期时间设置成24小时,同时通过监听写HBase Proxy来保证缓存的一致性,并将访问时间从十几分钟变成了秒级。 -
第三个是,上报过程中会上报不少非常规内容ID,这些内容ID在内容HBase中是不存储的,会造成缓存穿透的问题。所以在实时计算的时候,系统直接过滤掉这些内容ID,防止缓存穿透,又减少一些时间。 -
第四个是,因为设置了定时缓存,会引入一个缓存雪崩的问题。为了防止雪崩,我们在实时计算中,进行了削峰填谷的操作,错开设置缓存的时间。
-
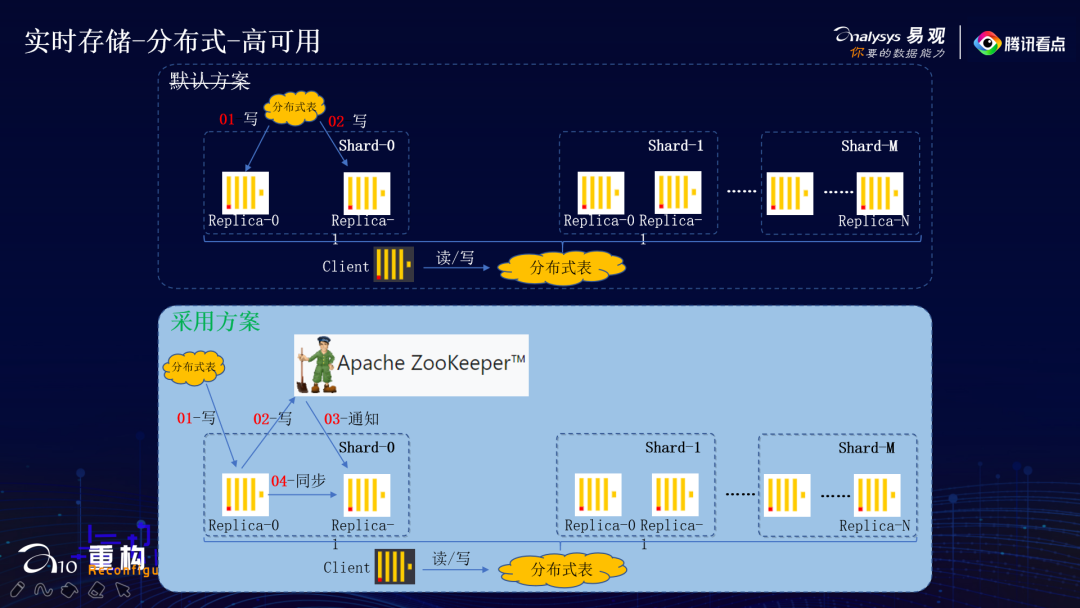
分布式-高可用
-
海量数据-写入
-
高性能-查询
版权声明及安全提醒:本文转自网络平台,文章仅代表作者观点,不代表「金融文库」立场。相关版权归原作者所有,「金融文库」仅提供免费交流与学习,相关内容与材料请勿用于商业。我们感谢每一位原创作者的辛苦付出与创作,如本转载内容涉及版权及侵权问题,请及时联系我们客服处理(微信号:JRwenku8),谢谢!


